文字列とUnicode
- JavaScriptは文字コードとしてUnicodeを採用し、エンコード方式としてUTF-16を採用しています。
- このUTF-16を採用しているのは、あくまでJavaScriptの内部で文字列を扱う際の文字コード(内部コード)です。 そのため、コードを書いたファイル自体の文字コード(外部コード)は、UTF-8のようにUTF-16以外の文字コードであっても問題ありません。
- JavaScriptのStringオブジェクトにはこの文字コード(Unicode)に特化したAPIもあります。 また、絵文字を含む特定の文字を扱う際や「文字数」を数えるという場合には、内部コードであるUTF-16を意識しないといけない場面があります。
Code Point
- Unicodeはすべての文字(制御文字などの画面に表示されない文字も含む)に対してIDを定義する目的で策定されている仕様です。 この「文字」に対する「一意のID」のことをCode Point(符号位置)と呼びます。
- ode Pointを扱うメソッドの多くは、ECMAScript 2015で追加されています。 ES2015で追加されたStringのcodePointAtメソッドやString.fromCodePoint静的メソッドを使うことで、文字列とCode Pointを相互変換できます。
// 文字列"あ"のCode Pointを取得
console.log("あ".codePointAt(0)); // => 12354
// Code Pointが`12354`の文字を取得する
console.log(String.fromCodePoint(12354)); // => "あ"
// `12354`を16進数リテラルで表記しても同じ結果
console.log(String.fromCodePoint(0x3042)); // => "あ"
Code PointとCode Unitの違い

// 文字列をCode Unit(16進数)の配列にして返す
function convertCodeUnits(str) {
const codeUnits = [];
for (let i = 0; i < str.length; i++) {
codeUnits.push(str.charCodeAt(i).toString(16));
}
return codeUnits;
}
// 文字列をCode Point(16進数)の配列にして返す
function convertCodePoints(str) {
return Array.from(str).map(char => {
return char.codePointAt(0).toString(16);
});
}
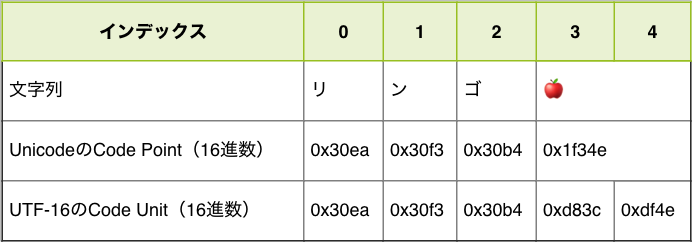
const str = "リンゴ";
const codeUnits = convertCodeUnits(str);
console.log(codeUnits); // => ["30ea", "30f3", "30b4", "d83c", "df4e"]
const codePoints = convertCodePoints(str);
console.log(codePoints); // => ["30ea", "30f3", "30b4", "1f34e"]
// Code Unit(上位サロゲート + 下位サロゲート)
console.log("\uD83C\uDF4E"); // => ""
// Code Point
console.log("\u{1F34E}"); // => ""
正規表現の.とUnicode
ES2015では、正規表現にu(Unicode)フラグが追加されました。 このuフラグをつけた正規表現は、文字列をCode Pointが順番に並んだものとして扱います。
実際にマッチした結果を見てみると、.はの下位サロゲートである\ude3dにマッチしていることがわかります(\ude3dは単独では表示できないため、文字化けのように表示されます)。
const [all, fish] = "のひらき".match(/(.)のひらき/);
console.log(all); // => "\ude3dのひらき"
console.log(fish); // => "\ude3d"
このような意図しない結果を避けるには、正規表現にuフラグをつけます。 uフラグがついた正規表現は、文字列をCode Pointごとに扱います。 そのため、任意の1文字にマッチする.がという文字(Code Point)にマッチします。
const [all, fish] = "のひらき".match(/(.)のひらき/u);
console.log(all); // => "のひらき"
console.log(fish); // => ""
基本的には正規表現にuフラグをつけて問題となるケースは少ないはずです。 なぜなら、サロゲートペアの片方だけにマッチしたい正規表現を書くケースはまれであるためです。
Code Pointの数を数える
Stringのlengthプロパティは、文字列を構成するCode Unitの個数を表すプロパティです。 そのためサロゲートペアを含む文字列では、lengthの結果が見た目より大きな値となる場合があります。
// Code Unitの個数を返す
console.log("".length); // => 2
console.log("\uD83C\uDF4E"); // => ""
console.log("\uD83C\uDF4E".length); // => 2
JavaScriptには、文字列におけるCode Pointの個数を数えるメソッドは用意されていません。 これを行うには、文字列をCode Pointごとに区切った配列へ変換して、配列の長さを数えるのが簡潔です。
Array.fromメソッド[ES2015]は、引数にiterableなオブジェクトを受け取り、それを元にした新しい配列を返します。 iterableオブジェクトとはSymbol.iteratorという特別な名前のメソッドを実装したオブジェクトの総称で、for…of文などで反復処理が可能なオブジェクトです(詳細は「ループと反復処理のfor…of文」を参照)。
文字列もiterableオブジェクトであるため、Array.fromメソッドによって1文字(厳密にはCode Point)ごとに区切った配列へと変換できます。先ほども紹介したように、文字列をiterableとして扱う場合はCode Pointごとに処理を行います。
// Code Pointごとの配列にする
// Array.fromメソッドはIteratorを配列にする
const codePoints = Array.from("リンゴ");
console.log(codePoints); // => ["リ", "ン", "ゴ", ""]
// Code Pointの個数を数える
console.log(codePoints.length); // => 4
ラッパーオブジェクト
プリミティブ型である文字列がStringのインスタンスメソッドを呼び出せるのは一見不思議です。
この章では、プリミティブ型の値がなぜオブジェクトのメソッドを呼び出せるのかについて解説します。
プリミティブ型とラッパーオブジェクト
プリミティブ型のデータのうち、真偽値(Boolean)、数値(Number) 、文字列(String)、シンボル(Symbol)にはそれぞれ対応するオブジェクトが存在します。たとえば、文字列に対応するオブジェクトとして、Stringオブジェクトがあります。
| ラッパーオブジェクト | プリミティブ型 | 例 |
|---|---|---|
| Boolean | 真偽値 | trueやfalse |
| Number | 数値 | 1や2 |
| BigInt BigInt | 1nや2n | |
| String | 文字列 | “文字列” |
| Symbol | シンボル | Symbol(“説明”) |
注記: undefinedとnullに対応するラッパーオブジェクトはありません。
“string”という文字列は、自動的にnew String(“string”)のようなラッパーオブジェクトへ変換されています。
ラッパーオブジェクト.valueOfメソッドを呼び出すことで、ラッパーオブジェクトから値を取り出せます。
const stringWrapper = new String("文字列");
// プリミティブ型の値を取得する
console.log(stringWrapper.valueOf()); // => "文字列"
ポイント
ラッパーオブジェクトをtypeof演算子で評価した結果が、プリミティブ型ではなく”object”となり混乱を生む
console.log(typeof new String("文字列")) // object
console.log(typeof "文字列") // string